


![]()
The future is open source everything.
—Linus Torvalds
That knowledge has become the resource, rather than a resource, is what makes our society post-capitalist.
—Peter Drucker, 1993
Imagine 1,000 people, broken up into groups of five, working on two hundred separate encyclopedias, versus that same number of people working on one encyclopedia? Which one will be the best? This sounds like a silly analogy when described in the context of an encyclopedia, but it is exactly what is going on in artificial intelligence (AI) research today.1
Some say free software doesn’t work in theory, but it does work in practice. In truth, it “works” in proportion to the number of people who are working together, and their collective efficiency. In early drafts of this book, I had positioned this chapter after the one explaining economic and legal issues around free software. However, I now believe it is important to discuss artificial intelligence separately and first, because AI is the holy-grail of computing, and the reason we haven’t solved AI is that there are no free software codebases that have gained critical mass. Far more than enough people are out there, but they are usually working in teams of one or two people, or proprietary codebases.
Deep Blue has been Deep-Sixed
Some people worry that artificial intelligence will make us feel inferior, but then, anybody in his right mind should have an inferiority complex every time he looks at a flower.
—Alan Kay, computer scientist
The source code for IBM’s Deep Blue, the first chess machine to beat then-reigning World Champion Gary Kasparov, was built by a team of about five people. That code has been languishing in a vault at IBM ever since because it was not created under a license that would enable further use by anyone, even though IBM is not attempting to make money from the code or using it for anything.
The second best chess engine in the world, Deep Junior, is also not free, and is therefore being worked on by a very small team. If we have only small teams of people attacking AI, or writing code and then locking it away, we are not going to make progress any time soon towards truly smart software.
Today’s chess computers have no true AI in them; they simply play moves, and then use human-created analysis to measure the result. If you were to go tweak the computer’s value for how much a queen is worth compared to a pawn, the machine would start losing and wouldn’t even understand why. It comes off as intelligent only because it has very smart chess experts programming the computer precisely how to analyze moves, and to rate the relative importance of pieces and their locations, etc.
Deep Blue could analyze two hundred million positions per second, compared to grandmasters who can analyze only 3 positions per second. Who is to say where that code might be today if chess AI aficionados around the world had been hacking on it for the last 10 years?
DARPA Grand Challenge
Proprietary software developers have the advantages money provides; free software developers need to make advantages for each other. I hope some day we will have a large collection of free libraries that have no parallel available to proprietary software, providing useful modules to serve as building blocks in new free software, and adding up to a major advantage for further free software development. What does society need? It needs information that is truly available to its citizens—for example, programs that people can read, fix, adapt, and improve, not just operate. But what software owners typically deliver is a black box that we can’t study or change. —Richard Stallman
The hardest computing challenges we face are man-made: language, roads and spam. Take, for instance, robot-driven cars. We could do this without a vision system, and modify every road on the planet by adding driving rails or other guides for robot-driven cars, but it is much cheaper and safer to build software for cars to travel on roads as they exist today — a chaotic mess.
At the annual American Association for the Advancement of Science (AAAS) conference in February 2007, the “consensus
” among the scientists was that we will have driverless cars by 2030. This prediction is meaningless because those working on the problem are not working together, just as those working on the best chess software are not working together. Furthermore, as American cancer researcher Sidney Farber has said, “Any man who predicts a date for discovery is no longer a scientist.”
Today, Lexus has a car that can parallel park itself, but its vision system needs only a very vague idea of the obstacles around it to accomplish this task. The challenge of building a robot-driven car rests in creating a vision system that makes sense of painted lines, freeway signs, and the other obstacles on the road, including dirtbags not following “the rules”.
The Defense Advanced Research Projects Agency (DARPA), which unlike Al Gore, really invented the Internet, has sponsored several contests to build robot-driven vehicles:

Stanley, Stanford University’s winning entry for the 2005 challenge. It might not run over a Stop sign, but it wouldn’t know to stop.
Like the parallel parking scenario, the DARPA Grand Challenge of 2004 required only a simple vision system. Competing cars traveled over a mostly empty dirt road and were given a detailed series of map points. Even so, many of the cars didn’t finish, or perform confidently. There is an expression in engineering called “garbage in, garbage out”; as such, if a car sees “poorly”, it is helpless.
What was disappointing about the first challenge was that an enormous amount of software was written to operate these vehicles yet none of it has been released (especially the vision system) for others to review, comment on, improve, etc. I visited Stanford’s Stanley website
and could find no link to the source code, or even information such as the programming language it was written in.
Some might wonder why people should work together in a contest, but if all the cars used rubber tires, Intel processors and the Linux kernel, would you say they were not competing? It is a race, with the fastest hardware and driving style winning in the end. By working together on some of the software, engineers can focus more on the hardware, which is the fun stuff.
The following is a description of the computer vision pipeline required to successfully operate a driverless car. Whereas Stanley’s entire software team involved only 12 part-time people, the vision software alone is a problem so complicated it will take an effort comparable in complexity to the Linux kernel to build it:
Image acquisition: Converting sensor inputs from 2 or more cameras, radar, heat, etc. into a 3-dimensional image sequence
Pre-processing: Noise reduction, contrast enhancement
Feature extraction: lines, edges, shape, motion
Detection/Segmentation: Find portions of the images that need further analysis (highway signs)
High-level processing: Data verification, text recognition, object analysis and categorization
The 5 stages of an image recognition pipeline.
A lot of software needs to be written in support of such a system:
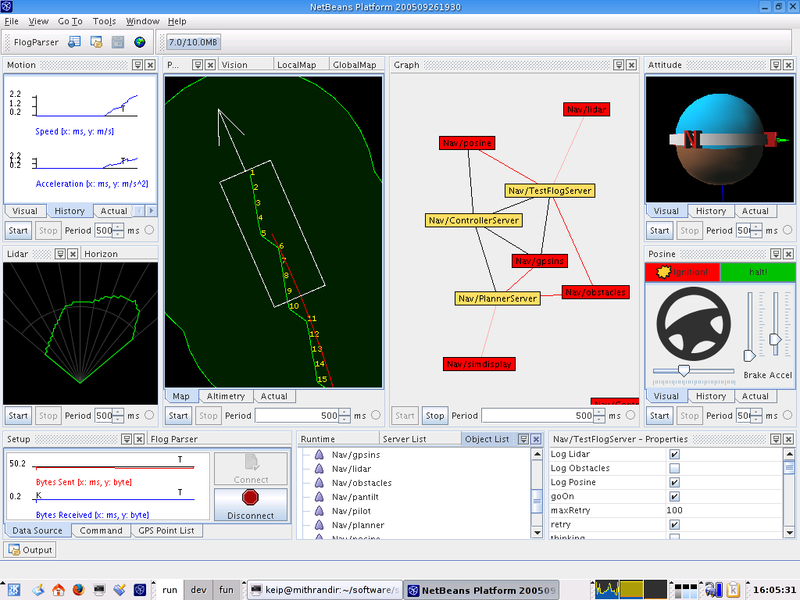
The vision pipeline is the hardest part of creating a robot-driven car, but even such diagnostic software is non-trivial.
In 2007, there was a new DARPA Urban challenge. This is a sample of the information given to the contestants:
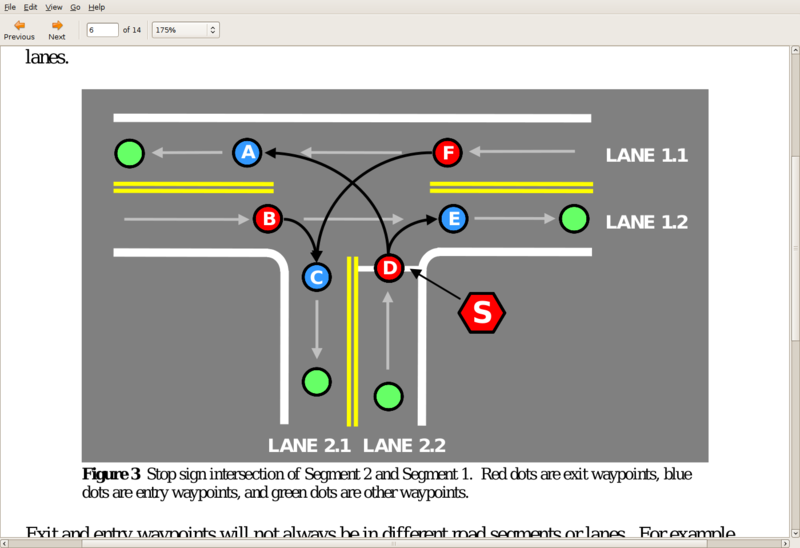
It is easier and safer to program a car to recognize a Stop sign than it is to point out the location of all of them.
Constructing a vision pipeline that can drive in an urban environment presents a much harder software problem. However, if you look at the vision requirements needed to solve the Urban Challenge, it is clear that recognizing shapes and motion is all that is required, and those are the same requirements as had existed in the 2004 challenge! But even in the 2007 contest, there was no more sharing than in the previous contest.
Once we develop the vision system, everything else is technically easy. Video games contain computer-controlled drivers that can race you while shooting and swearing at you. Their trick is that they already have detailed information about all of the objects in their simulated world.
After we’ve built a vision system, there are still many fun challenges to tackle: preparing for Congressional hearings to argue that these cars should have a speed limit controlled by the computer, or telling your car not to drive aggressively and spill your champagne, or testing and building confidence in such a system.2
Eventually, our roads will get smart. Once we have traffic information, we can have computers efficiently route vehicles around any congestion. A study
found that traffic jams cost the average large city $1 billion dollars a year.
No organization today, including Microsoft and Google, contains hundreds of computer vision experts. Do you think GM would be gutsy enough to fund a team of 100 vision experts even if they thought they could corner this market?
There are enough people worldwide working on the vision problem right now. If we could pool their efforts into one codebase, written in a modern programming language, we could have robot-driven cars in five years. It is not a matter of invention, it is a matter of engineering. Perhaps the world simply needs a Linus Torvalds of computer vision to step up and lead these efforts.
Software and the Singularity
Futurists talk about the “Singularity”, the time when computational capacity will surpass the capacity of human intelligence. Ray Kurzweil predicts it will happen in 2045.3
The flaw with any date estimate, other than the fact that they are always prone to extreme error, is that our software today has no learning capacity, because the idea of continuous learning is not yet a part of the foundation. Even the learning capabilities of an ant would be useful.
I believe the benefits inherent in the singularity will happen as soon as our software becomes “smart”. I don’t believe we need to wait for any further Moore’s law progress for that to happen. Computers today can do billions of operations per second, like add 123,456,789 and 987,654,321. Even if you could do that calculation in your head in one second, it would take you 30 years to do the billion that your computer can do in that second.
Even if you don’t think computers have the necessary hardware horsepower to be smart today, understand that in many scenarios, the size of the input is the driving factor to the processing power required. In image recognition, for example, the amount of work required to interpret an image is mostly a function of the size of the image. Each step in the image recognition pipeline, and the processes that take place in our brain, dramatically reduce the amount of data from the previous step. At the beginning of the analysis might be a one million pixel image, requiring 3 million bytes of memory. At the end of the analysis is the data that you are looking at your house, a concept that requires only 10 bytes to represent. The first step, working on the raw image, requires the most processing power, so therefore it is the image resolution (and frame rate) that set the requirements, values that are trivial to change. No one has shown robust vision recognition software running at any speed, on any sized image!
While a brain is different from a computer in that it does work in parallel, such parallelization only makes it happen faster, it does not change the result. Anything accomplished in our parallel brain could also be accomplished on computers of today, which can do only one thing at a time, but at the rate of billions per second. A 1-gigahertz processor can do 1,000 different operations on a million pieces of data in one second. With such speed, you don’t even need multiple processors! Even so, more parallelism is coming.4
Once we build software as smart as an ant, we will build software as smart as a human the same day, because it is the same software.
Google
One of the problems faced by the monopoly, as its leadership now well understands, is that any community that it can buy is weaker than the community that we have built.
In 1950, Alan Turing proposed a thought experiment as a definition of AI in which a computer’s responses (presumed to be textual) were so life-like that, after questioning, you could not tell whether they were made by a human or a computer. Right now the search experience is rather primitive, but eventually, your search engine’s response will be able to pass the Turing Test. Instead of simply doing glorified keyword matching, you could ask it to do things like: “Plot the population and GDP of the United States from 1900 – 2000.”5 Today, if you see such a chart, you know a human did a lot of work to make it. The creation of machines that can pass the Turing Test will make today’s challenge of outsourcing seem like small potatoes. Why outsource work to humans in other countries when computers nearby can do the task?
AI is a meaningless term in a sense because building a piece of software that will never lose at Tic-Tac-Toe is a version of AI, but it is a very primitive type of AI, entirely specified by a human and executed by a computer that is just following simple rules. Fortunately, the same primitive logic that can play Tic-Tac-Toe can be used to build arbitrarily “smart” software, like chess computers and robot-driven cars. We simply need to build systems with enough intelligence to fake it. This is known as “Weak AI”, as opposed to “Strong AI”, which is what we think about when we imagine robots that can pass the Turing Test, compose music, or get depressed. In Strong AI, you wouldn’t give this machine a software program to play chess, just the rules. The first application of Strong AI is Search; the pennies for web clicks can pay for the creation of intelligent computers.
The most important and interesting service on the Internet is search. Without an index, a database is useless — imagine a phone directory where the names were in random order. There is an enormous turf war taking place between Google, Yahoo!, and Microsoft for the search business. Google has 200,000 servers, which at 200 hits per second gives them the potential for three trillion transactions per day. Even with a quite typical quarter of a penny per ad impression, the potential revenue is huge. Right now, Google has 65% of the search business, with Yahoo! at 20% and Microsoft at 7%. Bill Gates has said that Microsoft is working merely to keep Google “honest”, which reveals his acceptance that, unlike Windows and Office, Microsoft’s search is not the leader. (Note that Microsoft’s online efforts have an inherent advantage over those who would also use Windows because they get unlimited software for free from themselves. Any other company which wanted to build services using Microsoft’s software would have higher costs.)
Furthermore, to supplant an incumbent, being 10% better is insufficient. It will take a major breakthrough by one of Google’s competitors to change the game. I use Google because I find its results good enough and because it keeps a search history, so that I can go back in time and retrieve past searches. If I started using a different search provider, I would lose this archive.
Part of the reason that Google is so profitable is because it uses lots of free software, but very little of their code is released to outsiders. Google’s source code is not freely available, and not for sale. In fact, Google is an extremely secretive and opaque company. Even in casual conversation at conferences, its engineers quickly retreat to statements about how everything is confidential. Ironically, a paper explaining PageRank, written in 1998 by Google co-founders Sergey Brin and Larry Page, says, “With Google, we have a strong goal to push more development and understanding into the academic realm.” It seems they have since had a change of heart.
Google has sufficient momentum and sophistication to stay ahead of its competitors. Here is a list of Google’s services:

Google is applying Metcalfe’s law to the web: Gmail is a good product, but being a part of the Google brand is half of its reason for success.
Even with all that Google is doing, search is its most important business though with Droid and stuff you wonder if they are forgetting that. Google has tweaked its patented PageRank algorithm extensively and privately since it was first introduced in 1998, but the core logic remains intact: The most popular web pages that match your search are the ones whose results are pushed to the top.7
PageRank lets the wisdom in millions of web sites decide what is the most popular, and therefore the best search result — because the computer cannot make that decision today. PageRank is an excellent stopgap measure to the problem of returning relevant information, but the focus should be on putting richer information into the database.
I believe software intelligence will get put into web spiders, those programs that crawl the Internet and process the pages. Right now, they mostly just index the location of words in a document, but eventually they will start to understand it, and build a database of knowledge, rather than a database of words. Much of the rest is a parsing issue. (Some early search engines, treated digits as words: searching for 1972 would find any reference to 1, 9, 7 or 2; this is clearly not a smart search algorithm.) The spiders that understand the information, because they’ve put it there, also become the librarians who take the search string you give it, and compare that to its knowledge.8 You need a librarian to build a library, and a librarian needs the library she built to help you. Today, web spiders are not getting a lot of attention in the search industry. Wikipedia documents 37 web crawlers, and it appears that the major focus for them is on performance and discovering link spam.9
The case for why a free search engine is better is a difficult one to make, so I will start with a simpler example, Google’s blogging software.
Blogger
While Google has 65% of the billion-dollar search business, it has 10% or less of the blog business. There exists an enormous number of blog sites, the code for which is basically all the same. The technology involved in running Instapundit.com, one of the most influential current-events blogs, is little different than that running Myspace, the most popular diary and chatboard for Jay-Z-listening teenage girls.
Google purchased the proprietary blogging engine Blogger in 2000 for an undisclosed amount. Google doesn’t release how many users they have because they consider that knowledge proprietary, but we do know that no community of hundreds of third party developers is working to extend Blogger to make it better and more useful.
The most popular free blogging engine is WordPress, a core of only 40,000 lines (400 pages) of code. It has no formal organization behind it, yet we find that just like Wikipedia and the Linux kernel, WordPress is reliable, rich, and polished:
WordPress, the most popular free blogging engine
WordPress is supported by a community of developers, who have created plug-ins, written and translated documentation, and designed many themes to customize the look. Here are the categories of plug-ins available for WordPress:
Administration Administration Tools Advertisement Anti-Spam Comments Meta (tagging) Restrictions Statistics Syntax Highlighting Syndication Translation and Languages Tweaking Monetizing Archive Calendar – Event Navigation Randomness Styles Widgets Links 3rd-parties services | Graphics, Video, and Sound Audio Images Multimedia Video Odds and Ends Financial Forums Geo Miscellaneous Mood Time Weather Outside Information Del.icio.us Technorati Posts Audio Posts Editing Posts Formatting Posts Miscellaneous Post Plugins |
There are hundreds of add-ons for WordPress that demonstrate the health of the developer community and which make it suitable for building even very complicated websites. This might look like a boring set of components, but if you broke apart MySpace or CNN’s website, you would find much of the same functionality.
Google acquired only six people when it purchased Pyra Labs, the original creators of Blogger, a number dwarfed by WordPress’s hundreds of contributors. As with any thriving ecosystem, the success of WordPress traces back to many different people tweaking, extending and improving shared code. Like everything else in the free software community, it is being built seemingly by accident.10
In addition to blogging software, I see other examples where Google could have worked more closely with the free software community with no threat to its business model. Recently I received many e-mails whose first words were: “Your cr. rating doesn’t matter” that I dutifully marked as spam. It took weeks before Gmail’s spam filter caught on. Spam is a very hard problem and cooperating with others could help improve Google faster, and lower their R&D costs. Some think that making spam filter software public will make it easier to make spam. But encryption algorithms are publicly documented and the consensus is that it makes them more secure because more people have looked at it and can all agree that the only way to decrypt is with the password. Likewise, all the popular algorithms use Bayesian-type analysis, and learn for each user what words are likely spam, which makes the job of a spammer much harder. The point is that giving this code away doesn’t actually help the spammers, who can even run tests with Google’s accounts to determine how it works.
Search
Google tells us what words mean, what things look like, where to buy things, and who or what is most important to us. Google’s control over “results” constitutes an awesome ability to set the course of human knowledge.
—Greg Lastowka, Professor of Law, Rutgers University
And I, for one, welcome our new Insect Overlords.
—News Anchorman Kent Brockman, The Simpsons
Why Google should have built Blogger as free software is an easier case to make because it isn’t strategic to Google’s business or profits, the search engine is a different question. Should Google have freed their search engine? I think a related, and more important question is this: Will it take the resources of the global software community to solve Strong AI and build intelligent search engines that pass the Turing Test?
Because search is an entire software platform, the best way to look at it is by examining its individual components. One of the most fundamental responsibilities for the Google web farm is to provide a distributed file system. The file system which manages the data blocks on one hard drive doesn’t know how to scale across machines to something the size of Google’s data. In fact, in the early days of Google, this was likely one of its biggest engineering efforts. There are (today) a number of free distributed file systems, but Google is not working with the free software community on this problem. One cannot imagine that a proprietary file system would provide Google any meaningful competitive advantage, nevertheless they have built one.
Another nontrivial task for a search engine is the parsing of PDFs, DOCs, and various other types of files in order to pull out the text to index them. It appears that this is also proprietary code that Google has written.
It is a lot easier to create a Google-scaled datacenter with all of its functionality using free software today than it was when Google was formed in 1998. Not only is Google not working with the free software community on the software they have created, they are actually the burdened first-movers. What you likely find running on a Google server is a base of Linux and other free software, upon which Google has created their custom, proprietary code. Google might think their proprietary software gives them an advantage, but it is mostly sucking up resources, and preventing them from leveraging advancements from outside developers.
And like Microsoft’s Windows NT kernel, even if Google were to release their infrastructure code, much of it would not be picked up because the free software community has developed their own solutions. In fact, in late 2006, Google began to release tiny bits and pieces of their most boring software, but when I looked at the codebases, there didn’t appear to be much contributions from the outside — because it isn’t nearly as interesting to the world as it would have been ten years earlier. Furthermore, as these codebases have lived inside Google for a long time they probably have lots of dependencies on other Google technologies which make it hard for it isolated and used in the outside world.
What about the core of Google’s business, the code that takes your search request and attempts to make sense of it so that it can pass the Turing Test? Google has not even begun to solve this problem, and even many simpler problems, so it makes one wonder if it is something a single company can solve by itself.
There are two kinds of engineering challenges for Google:
Those necessary, non-strategic, and at best loosely correlated to their profits, like blogging, language translation, and spam detection, none of which Google is cooperating with the community on.
Then there is the daunting problem of building software with Strong AI which Google had better be working on with the rest of the world. The idea of Google “owning” Strong AI is at least as scary as Microsoft owning Windows and Office. Google has publicly stated that Microsoft’s proprietary software model has been bad for the industry, but doesn’t recognize that it is trying to do the exact same thing!
Google is one of the few new, large, and fast-growing software businesses in America and few people are publicly arguing that the company give away the farm by sharing their core technology with the free software community. This is especially scary because it is an irreversible step. However, software is not a datacenter or a relationship with customers and advertisers. Most of the users of Google’s code would not be in competition with Google, but would be taking it to new places that they hadn’t considered. Furthermore, Google would still have a significant first-mover advantage of the code they created.
In addition, if someone else eventually creates a free search engine that a worldwide community of researchers coalesce around, where will Google be then? Perhaps Microsoft could flank Google by building a free search engine that scientists and researchers around the world could tinker in. There is an interesting free codebase called Lucene, run by the Apache foundation, which is steadily gaining use in Enterprises who want to run their own search engine. It seems quite possible that this is the codebase and community that will provide a threat to Google in five to ten years.
Conclusion

Comic from xkcd.com
There is reason for optimism about the scientific challenges we confront because the global community’s ability to solve problems is greater than the universe’s ability to create them. The truth waiting for us on the nature of matter, DNA, intelligence, etc. has been around for billions of years.
There are millions of computer scientists sitting around wondering why we haven’t yet solved the big problems in computer science. It should be no surprise that software is moving forward so slowly because there is such a lack of cooperation.
1 One website documents 60 pieces of source code that perform Fourier transformations, which is an important software building block. The situation is the same for neural networks, computer vision, and many other advanced technologies.
2 There are various privacy issues inherent in robot-driven cars. When computers know their location, it becomes easy to build a “black box” that would record all this information and even transmit it to the government. We need to make sure that machines owned by a human stay under his control, and do not become controlled by the government without a court order and a compelling burden of proof.
3 His prediction is that the number of computers, times their computational capacity, will surpass the number of humans, times their computational capacity, in 2045. Therefore, the world will be amazing then.
This calculation is flawed for several reasons:
We will be swimming in computational capacity long before 2040. Today, my computer is typically running at 2% CPU when I am using it, and therefore has 50 times more computational capacity than I need. An intelligent agent twice as fast as the previous one is not necessarily more useful.
Many of the neurons of the brain are not spent on reason, and so shouldn’t be in the calculations.
Billions of humans are merely subsisting, and are not plugged into the global grid, and so shouldn’t be measured.
There is no amount of continuous learning built in to today’s software.
Each of these would tend to push Singularity forward and support the argument that the benefits of singularity are not waiting on hardware. Humans make computers smarter, and computers make humans smarter, and this feedback loop makes 2045 a meaningless moment.
Who in the past fretted: “When will man build a device that is better at carrying things than me?” Computers will do anything we want, at any hour, on our command. A computer plays chess or music because we want it to. Robotic firemen will run into a burning building to save our pets. Computers have no purpose without us. We should worry about robots killing humans as much as we worry about someone stealing an Apache helicopter and killing humans today.
4 Most computers today contain a dual-core CPU and processor folks promise that 10 and more are coming. Intel’s processors also have limited 4-way parallel processing capabilities known as MMX and SSE. Intel could add even more of this parallel processing support if applications put them to better use. Furthermore, graphics cards exist to do work in parallel, and this hardware could also be adapted to AI if it is not usable already.
5 Of course, there are some interesting complexities to the GDP aspect, like whether to plot the GDP in constant dollars and per person.
6 Although Google doesn’t give away or sell their source code, they do sell an appliance for those who want a search engine for the documents on an internal Intranet. This appliance is a black box and is, by definition, managed separately than the other hardware and software in a datacenter.
It also doesn’t allow tight integration with internal applications. An example of a feature important to Intranets is to have the search engine index all documents I have access to. The Internet doesn’t really have this problem as basically everything is public. Applications are the only things that know who has access to all the data. It isn’t clear that Google has attacked this problem and because the appliance is not extensible, no one other than Google can fix this either. This feature is one reason why search engines should be exposed as part of an application.
7 Some of Google’s enhancements also include: freshness, which gives priority to recently-changed web pages. It also tries to classify queries into categories like places and products. Another new tweak is to not display too many results of one kind: they try to mix in news articles, advertisements, a Wikipedia entry, etc. These enhancements are nice, but are far from actually understanding what is in the articles, and it appears to be applying smarts to the search query rather than the data gathered by the spiders.
8 One might worry about how a spider that has only read a small portion of the Internet can help you with parts it has not seen? The truth is that these spiders all share a common memory.
9 Focusing on the spider side means continually adding new types of information into the database as it starts to understand things better. Let’s say you build a spider that can now understand dates and guess the publication date of the page. (This can be tricky when a web page contains biographical information and therefore many dates.) Spiders will then start to tag all the web pages it reads in the future with this new information. All of this tagging happens when the data is fetched, so that is where the intelligence needs to go.
10 In fact, WordPress’s biggest problem is that the 3rd party development is too rich, and in fact chaotic. There are hundreds of themes and plugins, many that duplicate each other’s functionality. But grocery stores offer countless types of toothpaste, and this has not been an insurmountable problem for consumers. I talk more about this topic in a later chapter.